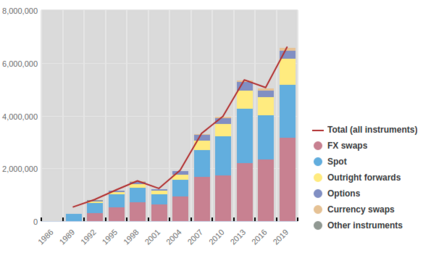
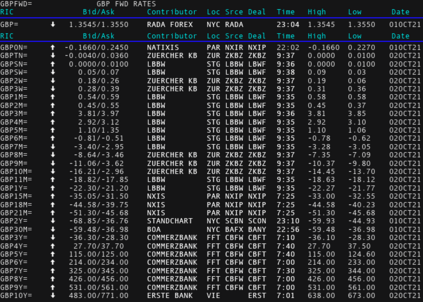
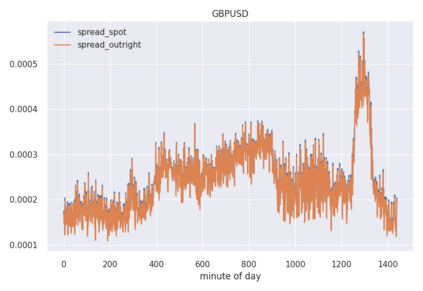
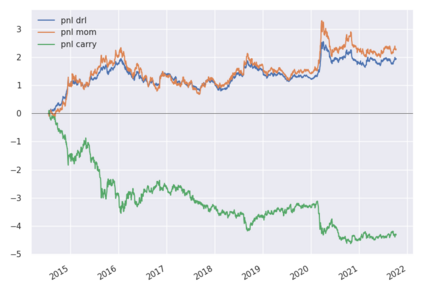
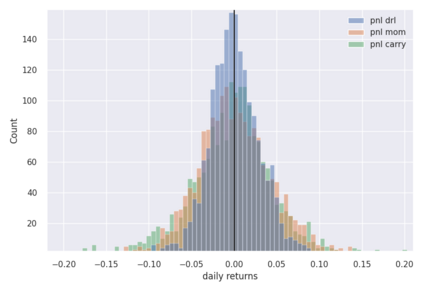
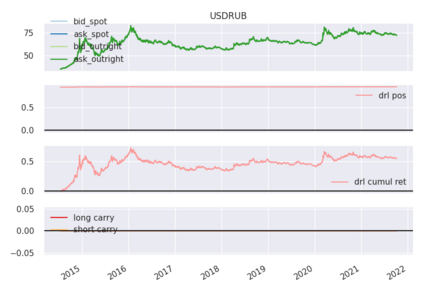
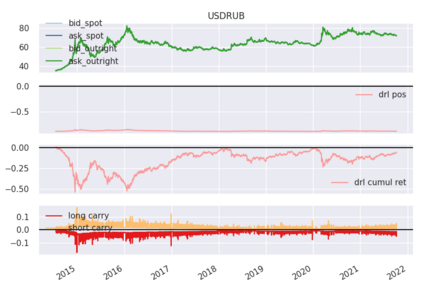
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
翻译:我们对主要的Fx现金配对进行详细的实验,准确核算交易和供资成本。这些利润和损失来源,包括货币市场的价格趋势,通过一种可直接瞄准位置的二次工具提供给我们经常性的加固学习者,这种工具学会直接瞄准一个位置。我们改进了先前的工作,在网上学习的背景下,将学习瞄准风险位置的问题推入网上学习。这种在线学习是按顺序先后进行,但也以转移学习的形式进行。我们把无线电基功能的输出输出,隐藏的处理单位,其手段、变异和总体规模由高斯混合模型决定,提供给经常性加固学习者和基线动力交易商。因此,我们经常学习的加固工具的内在性质被学习并提供给上游模型。我们不断加固的学习贸易商实现了0.52的年化组合信息比率,在7年测试模型中,除执行和供资成本外,还以转移方式进行。尽管在交易5月期结束时,交易成本、变异和总体规模由高斯混合模型决定,这些处理,其手段、变异性和总体规模由高斯混合模型决定,并提供给经常性的加西亚学习者和基线动力贸易商。这些结果与2008年以来的经常性贸易增值增长相比,这可以比重。这些结果比重反映了2008年的不断增长趋势的不断增长的不断增长的汇率变化的汇率趋势。这些结果反映了的汇率变化,这反映了了2008年的汇率变化的汇率趋势。