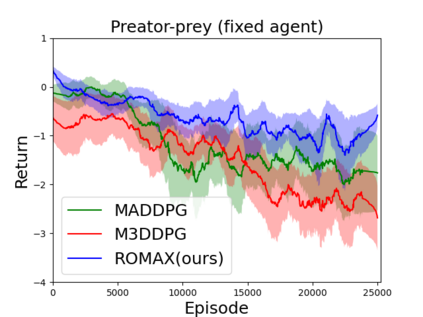
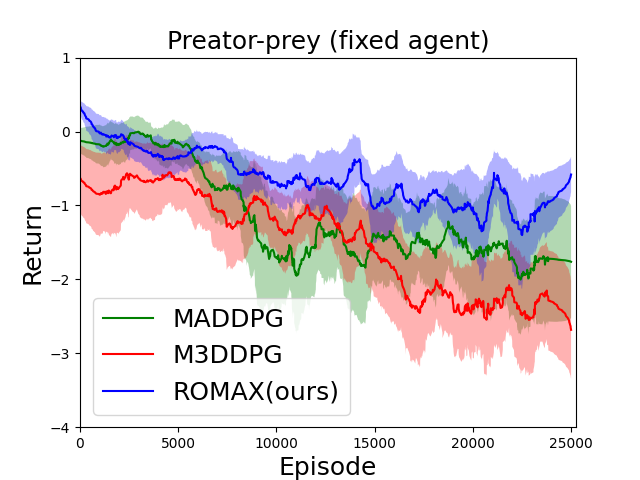
In a multirobot system, a number of cyber-physical attacks (e.g., communication hijack, observation perturbations) can challenge the robustness of agents. This robustness issue worsens in multiagent reinforcement learning because there exists the non-stationarity of the environment caused by simultaneously learning agents whose changing policies affect the transition and reward functions. In this paper, we propose a minimax MARL approach to infer the worst-case policy update of other agents. As the minimax formulation is computationally intractable to solve, we apply the convex relaxation of neural networks to solve the inner minimization problem. Such convex relaxation enables robustness in interacting with peer agents that may have significantly different behaviors and also achieves a certified bound of the original optimization problem. We evaluate our approach on multiple mixed cooperative-competitive tasks and show that our method outperforms the previous state of the art approaches on this topic.
翻译:在多机器人系统中,一些网络物理攻击(例如通信劫持、观察干扰)可以挑战代理人的稳健性。这种稳健性问题在多剂强化学习中恶化,因为同时存在的学习代理人对环境的不常态性是存在的,而他们不断变化的政策影响着过渡和奖励功能。在本文中,我们建议采用微缩式MARL方法来推断其他代理人最差的个案政策更新。由于微量分子配方在计算上难以解决,我们运用神经网络的松散来解决内部最小化问题。这种松散式放松使得与可能具有显著不同行为的同行代理人的互动更加稳健,并实现了原始优化问题的认证界限。我们评估了我们关于多种混合合作竞争任务的方法,并表明我们的方法比以前关于这一专题的艺术方法要好。