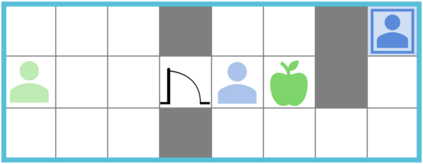
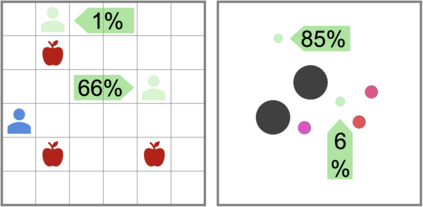
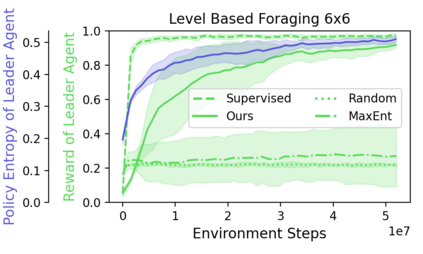
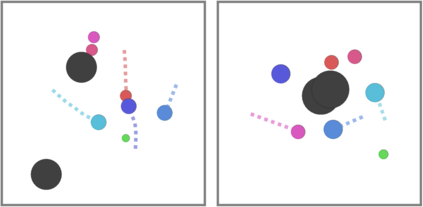
Can artificial agents learn to assist others in achieving their goals without knowing what those goals are? Generic reinforcement learning agents could be trained to behave altruistically towards others by rewarding them for altruistic behaviour, i.e., rewarding them for benefiting other agents in a given situation. Such an approach assumes that other agents' goals are known so that the altruistic agent can cooperate in achieving those goals. However, explicit knowledge of other agents' goals is often difficult to acquire. In the case of human agents, their goals and preferences may be difficult to express fully, may be ambiguous or even contradictory. Thus, it is beneficial to develop agents that do not depend on external supervision and can learn altruistic behaviour in a task-agnostic manner. We propose to act altruistically towards other agents by giving them more choice and thereby allowing them to better achieve their goals. Some concrete examples include opening a door for others or safeguarding them to pursue their objectives without interference. We formalize this concept and propose an altruistic agent that learns to increase the choices another agent has by preferring to maximize the number of states that the other agent can reach in its future. We evaluate our approach on three different multi-agent environments where another agent's success depends on the altruistic agent's behaviour. Finally, we show that our unsupervised agents can perform comparably to agents explicitly trained to work cooperatively, in some cases even outperforming them.
翻译:人工代理商能够学习帮助他人实现其目标而不知道这些目标是什么?一般强化学习代理商可以接受培训,通过以利他主义行为来奖励他人,即奖励他们在特定情况下为其他代理商谋利。这种方法假定其他代理商的目标是众所周知的,这样利他主义代理商可以合作实现这些目标。然而,明确了解其他代理商的目标往往很难获得。在人类代理商的情况下,他们的目标和偏好可能难以充分表达,可能是模糊的,甚至相互矛盾。因此,发展不依赖外部监督并能以任务不可知的方式学习利他主义行为的代理商是有益的。我们提议对其他代理商采取利他主义行为,给他们更多的选择,从而使他们能够更好地实现这些目标。一些具体的例子包括打开他人的大门,或者在不受干扰的情况下维护他们的目标。我们正式确定这一概念,并提议一个利他主义的代理商,学会增加另一个代理商的选择。我们宁愿使其他代理商的更多国家数量,而其他代理商最终能够展示另一个成功的竞争环境。我们评估的是,我们的代理商最终能够展示另一个成功的竞争环境。