【导读】今年 8 月份,毕业于斯坦福、现就职于英伟达人工智能应用团队的 Chip Huyen 撰写了一篇博客,讲述她对NeurlPS2019的观感,讲述了研究热点与发展趋势,感兴趣的三个方向是: 贝叶斯学习、图神经网络和凸优化,来看下。
地址: https://huyenchip.com/2019/12/18/key-trends-neurips-2019.html
- 深度学习与贝叶斯原理
正如Emtiyaz Khan在他的《深度学习与贝叶斯原则》演讲中所强调的那样,贝叶斯学习和深度学习是非常不同的。根据Khan的说法,深度学习使用“试错”的方法——让我们看看实验会把我们带向何方——而贝叶斯原则迫使你事先思考一个假设(先验)。
与常规的深度学习相比,贝叶斯深度学习主要有两个优点:不确定性估计和对小数据集的更好的泛化。在实际应用中,仅仅系统做出预测是不够的。知道每个预测的确定性是很重要的。例如,预测癌症有50.1%的确定性需要不同的治疗,同样的预测有99.9%的确定性。在贝叶斯学习中,不确定性估计是一个内置特性。
传统的神经网络给出单点估计——它们使用一组权值在数据点上输出预测。另一方面,Bayesian神经网络使用网络权值上的概率分布,并输出该分布中所有权值集的平均预测,其效果与许多神经网络上的平均预测相同。因此,贝叶斯神经网络是自然的集合体,它的作用类似于正则化,可以防止过度拟合。
拥有数百万参数的贝叶斯神经网络的训练在计算上仍然很昂贵。收敛到一个后验值可能需要数周时间,因此诸如变分推论之类的近似方法已经变得流行起来。概率方法-变分贝叶斯推理会议上发表了10篇关于这种变分贝叶斯方法的论文。
我喜欢读一些关于贝叶斯深度学习的NeurIPS论文:
- Importance Weighted Hierarchical Variational Inference,https://arxiv.org/abs/1905.03290
- A Simple Baseline for Bayesian Uncertainty in Deep Learning,https://arxiv.org/abs/1902.02476
- Practical Deep Learning with Bayesian Principles,https://arxiv.org/abs/1906.02506
- 图神经网络(GNNs)
多年来,我一直在谈论图论是机器学习中最被低估的话题之一。我很高兴看到图机器学习在今年的NeurIPS上非常流行。
对于许多类型的数据,例如社交网络、知识库和游戏状态,图形是美丽而自然的表示。用于推荐系统的用户项数据可以表示为一个二部图,其中一个不相交集由用户组成,另一个由物品组成。
图也可以表示神经网络的输出。正如 Yoshua Bengio在他的特邀演讲中提醒我们的那样,任何联合分布都可以表示为一个因子图。
这使得graph neural network对于组合优化(例如旅行推销员、日程安排)、身份匹配(这个Twitter用户和这个Facebook用户一样吗?)、推荐系统等任务来说是完美的。
最流行的图神经网络是图卷积神经网络(GCNN),这是预期的,因为它们都对本地信息进行编码。卷积倾向于寻找输入相邻部分之间的关系。图通过边编码与输入最相关的部分。
- Exact Combinatorial Optimization with Graph Convolutional Neural Networks,https://arxiv.org/abs/1906.01629
- Yes, there’s a paper that fuses two hottest trends this year: Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels,https://arxiv.org/abs/1905.13192
- My favorite poster presentation at NeurIPS: (Nearly) Efficient Algorithms for the Graph Matching Problem on Correlated Random Graphs,https://arxiv.org/abs/1805.02349
推荐阅读:
- Thomas N. Kipf’s Graph Convolutional Networks blog post,https://tkipf.github.io/graph-convolutional-networks/
- Kung-Hsiang, Huang’s A Gentle Introduction to Graph Neural Networks (Basics, DeepWalk, and GraphSage),https://towardsdatascience.com/a-gentle-introduction-to-graph-neural-network-basics-deepwalk-and-graphsage-db5d540d50b3
- 凸优化
我很欣赏Stephen Boyd关于凸优化的工作,所以很高兴看到它在NeurIPS上越来越受欢迎——有32篇论文与这个主题相关(1,2)。Stephen Boyd和J. Zico Kolter的实验室也发表了他们的论文《可微凸优化层》,展示了如何通过凸优化问题的解决方案进行区分,使其有可能嵌入可微程序(如神经网络)并从数据中学习它们。
凸优化问题是有吸引力的,因为它们可以准确地解决(1e-10的误差容忍度是可以实现的)和快速。它们也不会产生奇怪的/意料之外的输出,而这对于真实的应用程序是至关重要的。尽管在开放环境遇到的许多问题都是非凸的,但将它们分解成一系列凸问题是可行的。
利用凸优化算法训练神经网络。然而,虽然神经网络的重点是从头开始学习,但在端到端的方式中,凸优化问题的应用明确地强调建模系统,使用领域特定的知识。当可以以凸的方式显式地对系统建模时,通常需要的数据要少得多。可微凸优化层的工作是混合端到端学习和显式建模的优点的一种方法。
当你想控制一个系统的输出时,凸优化特别有用。例如,SpaceX使用凸优化来让火箭着陆,贝莱德(BlackRock)将其用于交易算法。在深度学习中使用凸优化真的很酷,就像现在的贝叶斯学习。
Akshay Agrawal推荐的关于凸优化的NeurIPS论文。
- Acceleration via Symplectic Discretization of High-Resolution Differential Equations,https://papers.nips.cc/paper/8811-acceleration-via-symplectic-discretization-of-high-resolution-differential-equations
- Hamiltonian descent for composite objectives,http://papers.nips.cc/paper/9590-hamiltonian-descent-for-composite-objectives
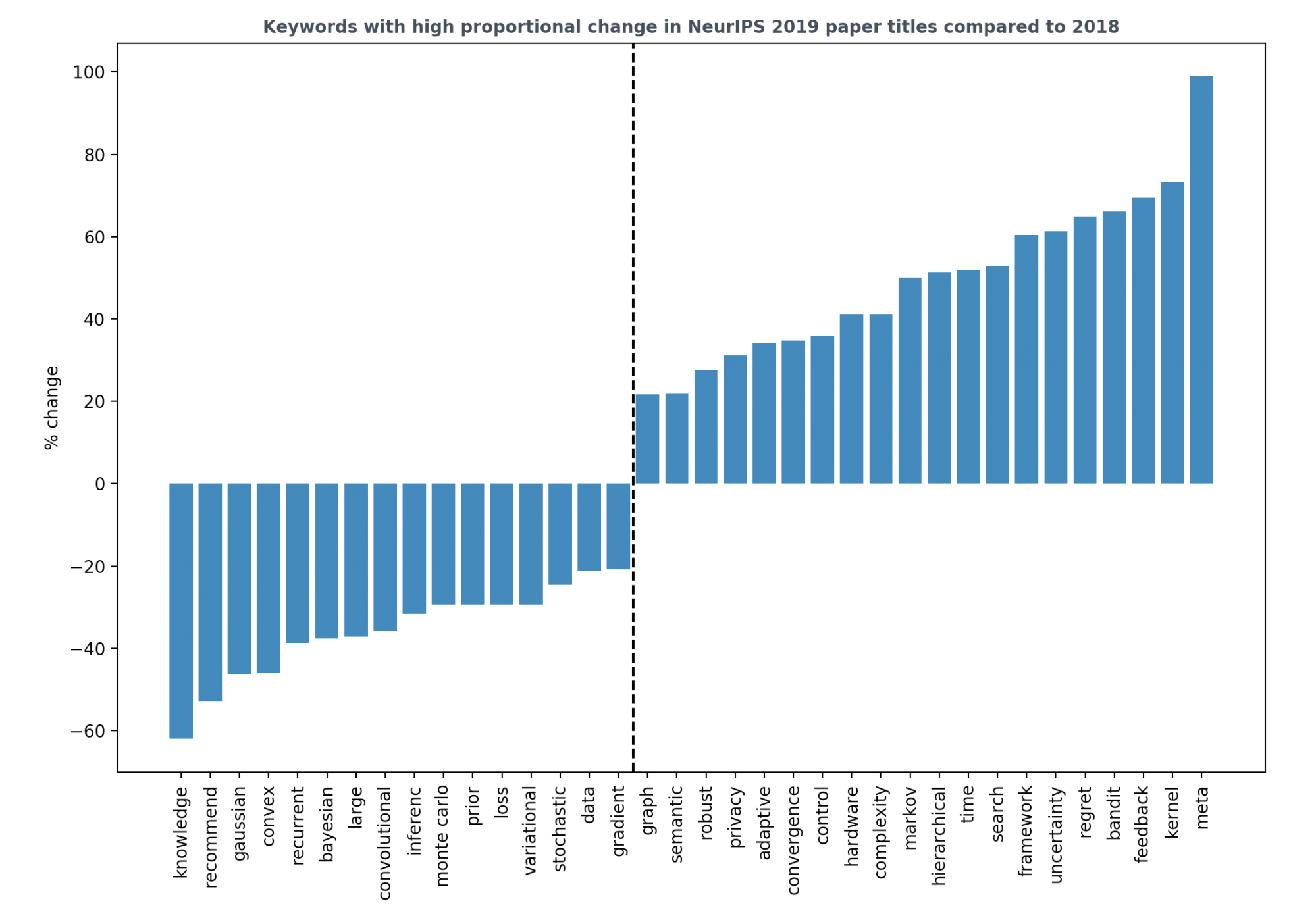
NeurlPS 2019 研究内容分析
- 强化学习甚至在机器人学之外也越来越流行。有显著正性变化的关键词有bandit、feedback、regret、control。
- 生成模型仍然很流行。GAN仍然吸引着我们的想象力,但远没有那么夸张。
- 递归神经网络和卷积神经网络在去年确实如此。
- 硬件关键字也在上升,信号更多的硬件感知算法。这是对硬件是机器学习瓶颈这一担忧的回答。
- 我很难过数据在下降。
- Meta learning预计,今年这一比例的增幅最高。
- 尽管贝叶斯定理下降了,不确定性却上升了。去年,有很多论文使用了贝叶斯原理,但没有针对深度学习。
参考链接: https://huyenchip.com/2019/12/18/key-trends-neurips-2019.html