
论文题目: Knowledge Graph Alignment Network with Gated Multi-hop Neighborhood Aggregation
论文摘要
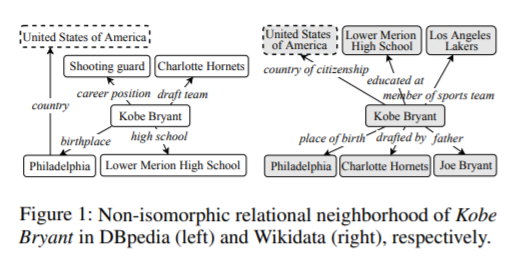
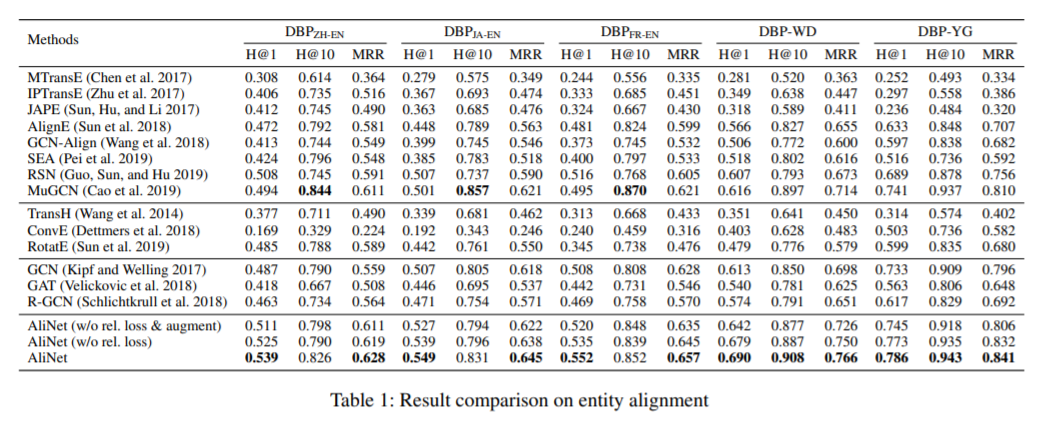
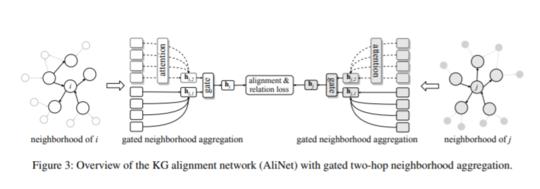
图神经网络由于具有识别同构子图的能力,已经成为一种强大的基于嵌入的实体对齐范式。然而,在真实知识图(KGs)中,通常是对应的实体 具有非同构的邻域结构,这很容易导致GNN产生不同的表示。为了解决这一问题,我们提出了一种新的KG对齐网络,即AliNet,旨在以端到端方式缓解邻域结构的非同构性。由于模式异构性,对等实体的直接邻域通常是不相似的,AliNet引入了远程邻域来扩展它们的邻域结构之间的重叠。它采用了一种注意机制,以突出有益的遥远的邻域和减少噪音。然后,利用门控机制控制直接和远处邻域信息的聚合。我们进一步提出了一个关系损失来细化实体表示。我们进行了深入的实验,详细的研究和分析的五个实体对齐数据集,证明了AliNet的有效性。
论文作者
孙泽群是南京大学计算机科学与技术系在读博士,目前在南京大学软件新技术国家重点实验室,博士导师为胡伟副教授。
胡伟,博士,南京大学计算机科学与技术系副教授,博士生导师。2005年、2009年分别于东南大学计算机科学与工程学院获学士、博士学位。2009年12月加入南京大学工作至今。研究领域为知识挖掘,数据集成,智能软件。
成为VIP会员查看完整内容


相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
102+阅读 · 2019年11月24日
Arxiv
19+阅读 · 2019年11月20日
Arxiv
12+阅读 · 2019年9月26日
Arxiv
6+阅读 · 2019年8月17日
Arxiv
7+阅读 · 2018年11月4日




相关VIP内容
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
102+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
19+阅读 · 2019年11月20日
Arxiv
12+阅读 · 2019年9月26日
Arxiv
6+阅读 · 2019年8月17日
Arxiv
7+阅读 · 2018年11月4日