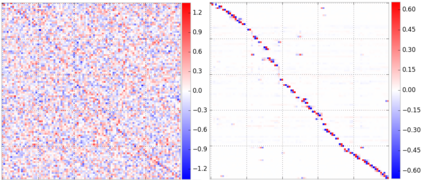
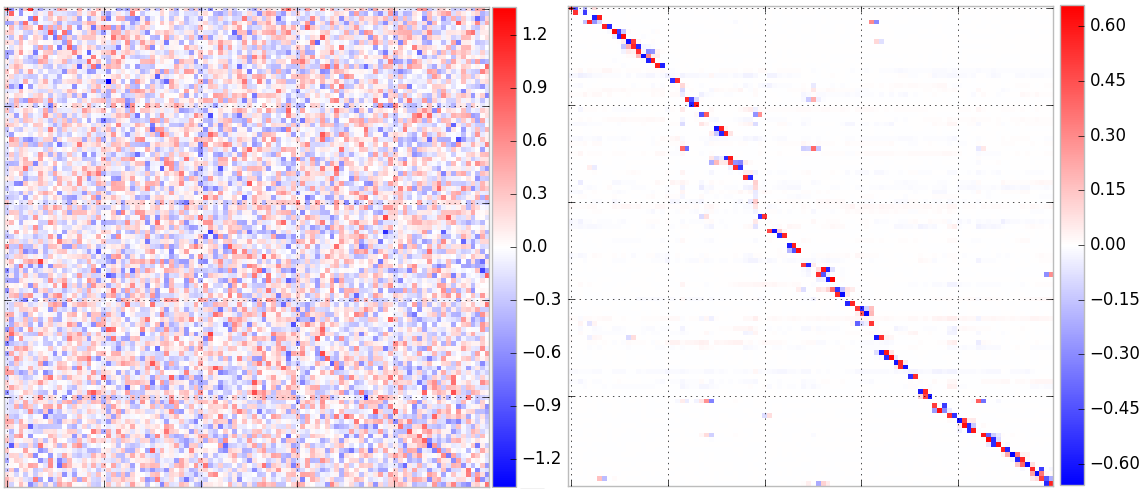
This paper presents OptNet, a network architecture that integrates optimization problems (here, specifically in the form of quadratic programs) as individual layers in larger end-to-end trainable deep networks. These layers encode constraints and complex dependencies between the hidden states that traditional convolutional and fully-connected layers often cannot capture. In this paper, we explore the foundations for such an architecture: we show how techniques from sensitivity analysis, bilevel optimization, and implicit differentiation can be used to exactly differentiate through these layers and with respect to layer parameters; we develop a highly efficient solver for these layers that exploits fast GPU-based batch solves within a primal-dual interior point method, and which provides backpropagation gradients with virtually no additional cost on top of the solve; and we highlight the application of these approaches in several problems. In one notable example, we show that the method is capable of learning to play mini-Sudoku (4x4) given just input and output games, with no a priori information about the rules of the game; this highlights the ability of our architecture to learn hard constraints better than other neural architectures.
翻译:本文展示了OptNet, 这个网络架构将优化问题( 具体以四级程序的形式) 整合为在更大的端到端可培训的深层网络中的单个层。 这些层将传统革命和完全连接的层往往无法捕捉的隐藏状态之间的制约和复杂依赖性编码成册。 在本文中, 我们探索了这种架构的基础: 我们展示了如何利用敏感度分析、双级优化和隐含差异的技术, 来通过这些层和层参数来进行精确区分; 我们为这些层开发了一个高效的解决方案, 利用基于快速 GPU 的批量解决方案, 在原始二极内点方法中, 并且提供反向回向回向回向回向回路的梯度, 而在解决方案的顶端几乎没有额外的费用; 我们强调这些方法在几个问题上的应用。 在一个显著的例子中, 我们显示, 方法能够学习微型- Sudoku (4x4) 玩小型- Sudoku ( ) 的方法, 仅仅因为有投入和输出游戏的规则, 没有关于游戏规则的先有信息; 这突出我们的建筑结构学习比其他神经结构更好的硬性制约的能力 。