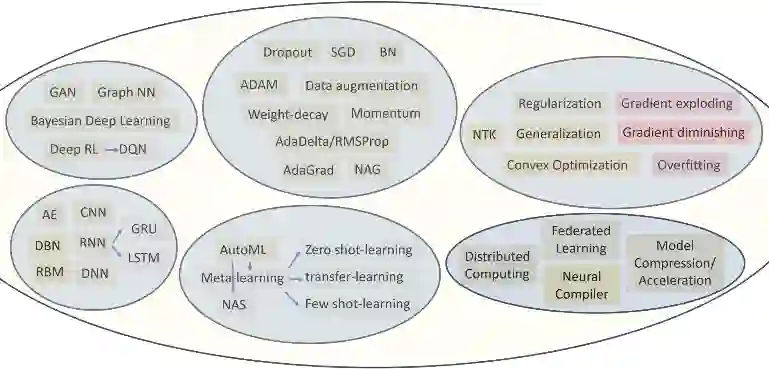
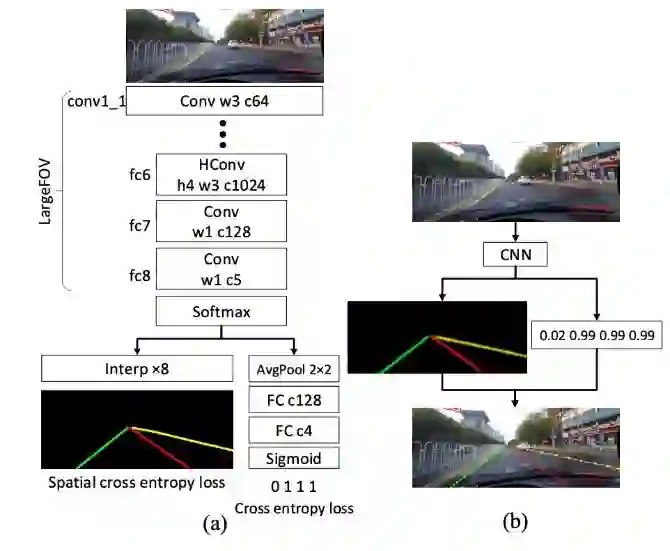
Since DARPA Grand Challenges (rural) in 2004/05 and Urban Challenges in 2007, autonomous driving has been the most active field of AI applications. Almost at the same time, deep learning has made breakthrough by several pioneers, three of them (also called fathers of deep learning), Hinton, Bengio and LeCun, won ACM Turin Award in 2019. This is a survey of autonomous driving technologies with deep learning methods. We investigate the major fields of self-driving systems, such as perception, mapping and localization, prediction, planning and control, simulation, V2X and safety etc. Due to the limited space, we focus the analysis on several key areas, i.e. 2D and 3D object detection in perception, depth estimation from cameras, multiple sensor fusion on the data, feature and task level respectively, behavior modelling and prediction of vehicle driving and pedestrian trajectories.
翻译:自2004/2005年度DARPA重大挑战(农村)和2007年城市挑战以来,自主驾驶一直是AI应用中最活跃的领域,几乎同时,一些先驱者(其中3人(也称为深层学习的父亲)、Hinton、Bengio和LeCun于2019年获得ACM都灵奖。这是对自主驾驶技术及其深层学习方法的调查。我们调查了自我驾驶系统的主要领域,如感知、绘图和定位、预测、规划和控制、模拟、V2X和安全等。由于空间有限,我们集中分析了几个关键领域,即2D和3D物体的感知探测、摄像头的深度估计、关于数据、特征和任务层次的多传感器混集、车辆驾驶和行车轨的行为建模和预测。