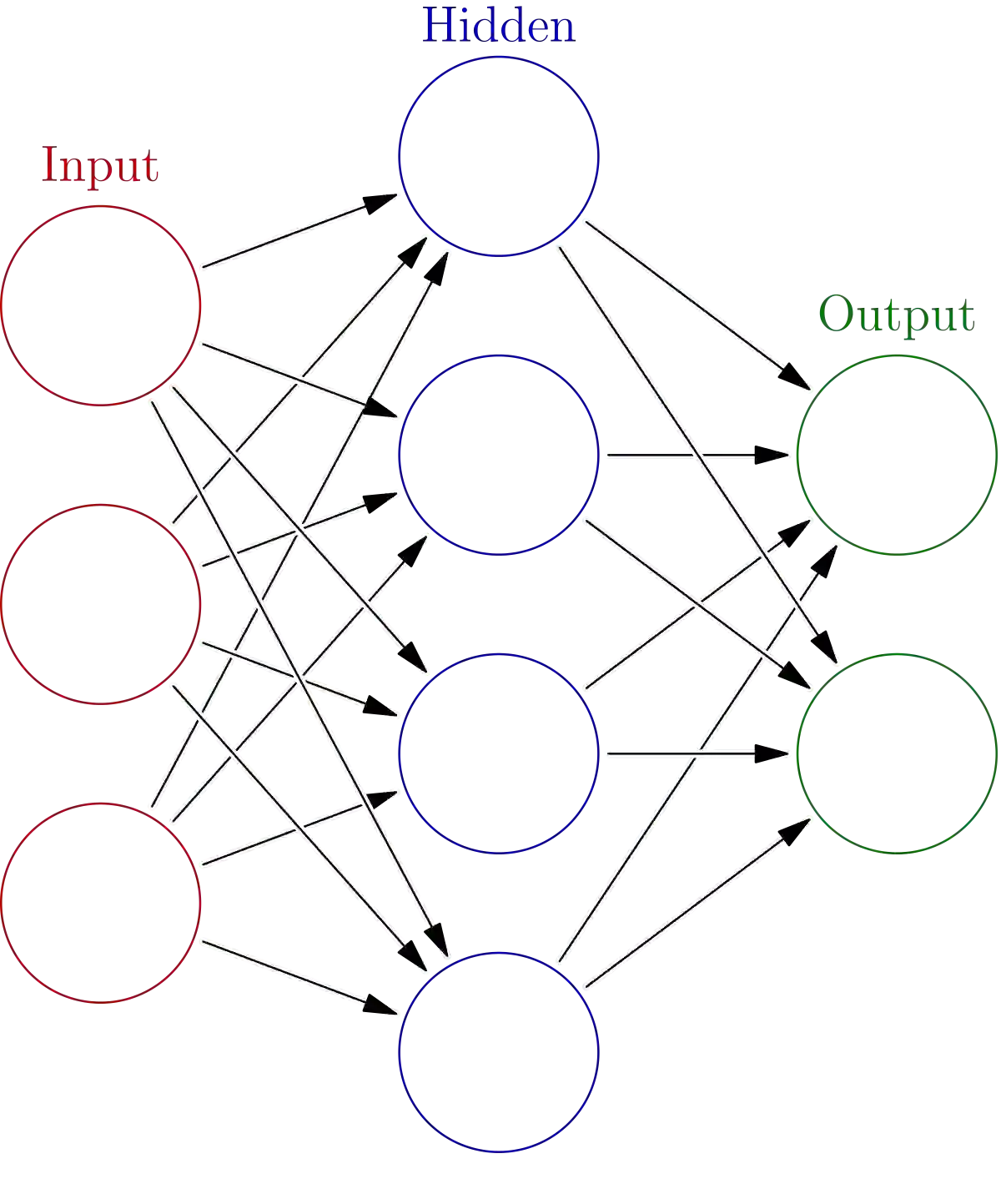
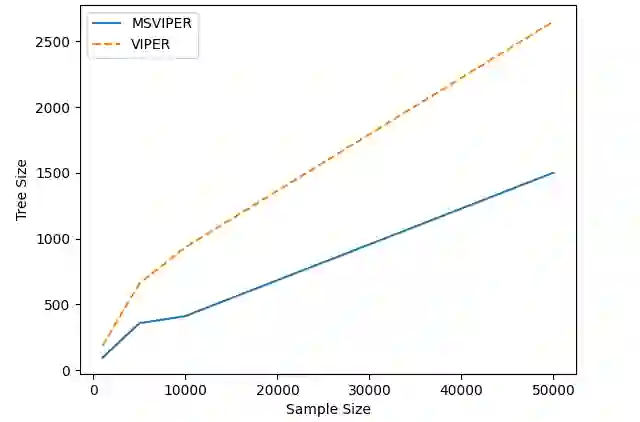
We present Multiple Scenario Verifiable Reinforcement Learning via Policy Extraction (MSVIPER), a new method for policy distillation to decision trees for improved robot navigation. MSVIPER learns an "expert" policy using any Reinforcement Learning (RL) technique involving learning a state-action mapping and then uses imitation learning to learn a decision-tree policy from it. We demonstrate that MSVIPER results in efficient decision trees and can accurately mimic the behavior of the expert policy. Moreover, we present efficient policy distillation and tree-modification techniques that take advantage of the decision tree structure to allow improvements to a policy without retraining. We use our approach to improve the performance of RL-based robot navigation algorithms for indoor and outdoor scenes. We demonstrate the benefits in terms of reduced freezing and oscillation behaviors (by up to 95\% reduction) for mobile robots navigating among dynamic obstacles and reduced vibrations and oscillation (by up to 17\%) for outdoor robot navigation on complex, uneven terrains.
翻译:通过政策采掘(MSVIPER),我们提出了多设想的通过政策强化学习(多设想的通过政策强化学习)的新政策蒸馏方法(MSVIPER),这是用于改进机器人导航的决策树的一种新的政策蒸馏方法。MSVIPER学会了一种“专家”政策,使用了任何强化学习(RL)技术,包括学习州-行动绘图,然后使用仿真学习学习来从中学习决策树政策。我们证明MSVIPER产生高效的决策树,可以准确地模仿专家政策的行为。此外,我们提出了有效的政策蒸馏和植树技术,利用决策树结构来改进政策,而无需再培训。我们利用我们的方法改进基于RL的室内和室外机器人导航算法的性。我们展示了减少冷冻和振动行为(最多为95 ⁇ )的好处,用于移动机器人在动态障碍之间航行,减少振动和振动(最多为17 ⁇ ),用于在复杂、不均匀的地形上进行户外机器人导航。