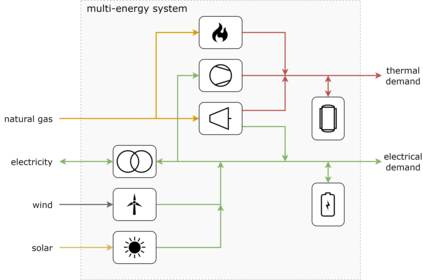
Reinforcement learning (RL) is a promising optimal control technique for multi-energy management systems. It does not require a model a priori - reducing the upfront and ongoing project-specific engineering effort and is capable of learning better representations of the underlying system dynamics. However, vanilla RL does not provide constraint satisfaction guarantees - resulting in various potentially unsafe interactions within its safety-critical environment. In this paper, we present two novel safe RL methods, namely SafeFallback and GiveSafe, where the safety constraint formulation is decoupled from the RL formulation. These provide hard-constraint, rather than soft- and chance-constraint, satisfaction guarantees both during training a (near) optimal policy (which involves exploratory and exploitative, i.e. greedy, steps) as well as during deployment of any policy (e.g. random agents or offline trained RL agents). This without the need of solving a mathematical program, resulting in less computational power requirements and a more flexible constraint function formulation (no derivative information is required). In a simulated multi-energy systems case study we have shown that both methods start with a significantly higher utility (i.e. useful policy) compared to a vanilla RL benchmark and Optlayer benchmark (94,6% and 82,8% compared to 35,5% and 77,8%) and that the proposed SafeFallback method even can outperform the vanilla RL benchmark (102,9% to 100%). We conclude that both methods are viably safety constraint handling techniques applicable beyond RL, as demonstrated with random policies while still providing hard-constraint guarantees.
翻译:强化学习( RL) 是多能源管理系统中最有希望的最佳控制技术。 它不需要先验性的模式 — — 减少前期和当前具体项目的工程努力,并且能够学习更好的系统动态表征。 但是, Vasilla RL 不提供约束性满意度保证---- 导致在其安全危急环境中出现各种潜在的不安全互动。 在本文中, 我们介绍了两种新型的安全安全 RL 方法, 即Safe Fallback 和 GeletSafe, 安全限制配方与RL 配方脱钩。 这些方法提供了硬约束, 而不是软和机会约束。 在培训( 接近) 最佳政策( 涉及探索性和剥削性, 贪婪, 步骤) 以及部署任何政策( 例如随机剂或离线培训 RL 代理) 时, 都提供了满意度保障。 这不需要解决数学程序, 导致计算能力要求更少, 限制功能也更灵活( 不需要衍生信息 ) 。 在模拟多能源系统案例研究中, 我们证明, 两种方法都比R8858 和 Van- 5 标准方法都比标准标准( 5 ( ) 和 Van- bregle) 5 (i) 5 (i) 都比 标准 和 Ve) 5 ( 标准, 和 Van- breal) 5 (i) 5) 5) 5 (比标准 5) 5 (比 标准 5 5 5 5 (比 标准 标准 5) 5) 。