
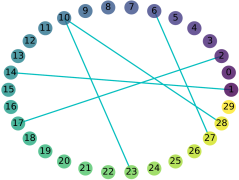
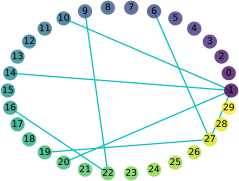
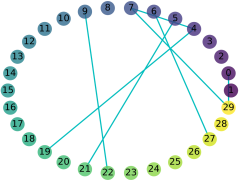
Exploring the intrinsic interconnections between the knowledge encoded in PRe-trained Deep Neural Networks (PR-DNNs) of heterogeneous tasks sheds light on their mutual transferability, and consequently enables knowledge transfer from one task to another so as to reduce the training effort of the latter. In this paper, we propose the DEeP Attribution gRAph (DEPARA) to investigate the transferability of knowledge learned from PR-DNNs. In DEPARA, nodes correspond to the inputs and are represented by their vectorized attribution maps with regards to the outputs of the PR-DNN. Edges denote the relatedness between inputs and are measured by the similarity of their features extracted from the PR-DNN. The knowledge transferability of two PR-DNNs is measured by the similarity of their corresponding DEPARAs. We apply DEPARA to two important yet under-studied problems in transfer learning: pre-trained model selection and layer selection. Extensive experiments are conducted to demonstrate the effectiveness and superiority of the proposed method in solving both these problems. Code, data and models reproducing the results in this paper are available at \url{https://github.com/zju-vipa/DEPARA}.
翻译:探索在PRE-DNN(PR-DNN)不同任务深深神经网络(PR-DNNNs)中编码的知识之间的内在相互联系,可以说明这些不同任务的相互可转让性,从而能够将知识从一个任务转移到另一个任务,从而减少后者的培训努力。在本文件中,我们建议DEP归并 graph(DEPARA)调查从PR-DNNs获得的知识的可转让性。在DEPARA中,节点与投入相对应,并以其与PR-DNNN产出有关的传导归属图为代表。 Edges表示投入之间的关联性,并以从PR-DNNN中提取的相似性来衡量。两个PR-DNNS的知识转移能力以其相应的DEPARAs的类似性来衡量。我们将DEPARAA应用于转让学习中两个重要但尚未得到研究的问题:经过预先培训的模型选择和层层选择。进行了广泛的实验,以证明拟议的方法在解决这些问题方面的有效性和优越性。 重印该文件结果的模型可在http://DAR_Qurz。




























相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

