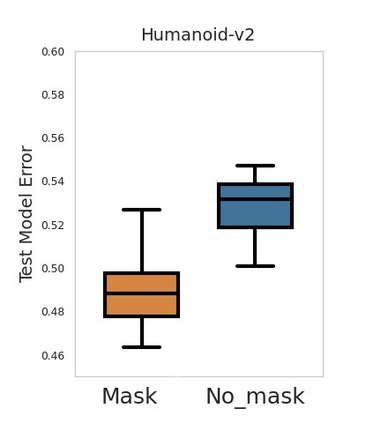
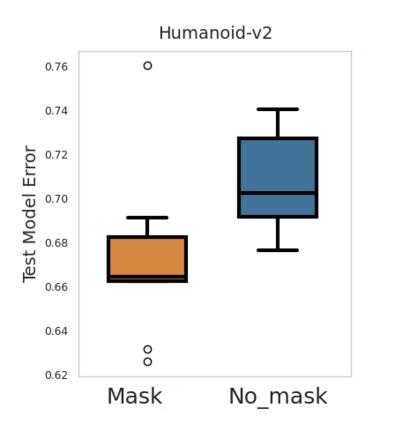
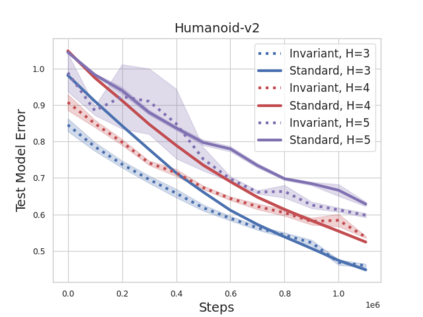
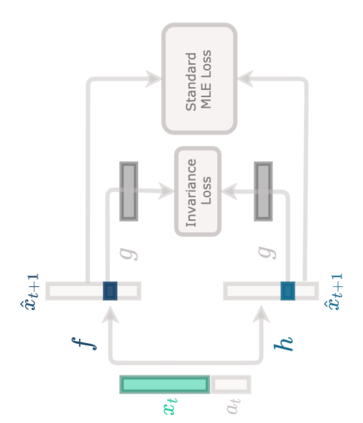
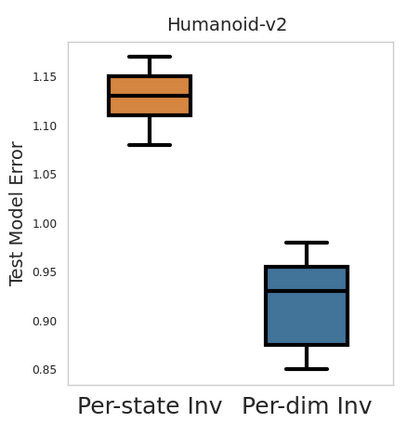
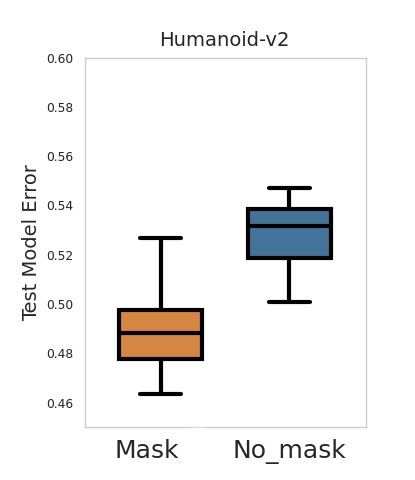
Accuracy and generalization of dynamics models is key to the success of model-based reinforcement learning (MBRL). As the complexity of tasks increases, so does the sample inefficiency of learning accurate dynamics models. However, many complex tasks also exhibit sparsity in the dynamics, i.e., actions have only a local effect on the system dynamics. In this paper, we exploit this property with a causal invariance perspective in the single-task setting, introducing a new type of state abstraction called \textit{model-invariance}. Unlike previous forms of state abstractions, a model-invariance state abstraction leverages causal sparsity over state variables. This allows for compositional generalization to unseen states, something that non-factored forms of state abstractions cannot do. We prove that an optimal policy can be learned over this model-invariance state abstraction and show improved generalization in a simple toy domain. Next, we propose a practical method to approximately learn a model-invariant representation for complex domains and validate our approach by showing improved modelling performance over standard maximum likelihood approaches on challenging tasks, such as the MuJoCo-based Humanoid. Finally, within the MBRL setting we show strong performance gains with respect to sample efficiency across a host of other continuous control tasks.
翻译:动态模型的准确性和概括性是基于模型的强化学习(MBRL)成功的关键。随着任务的复杂性增加,学习准确动态模型的抽样效率低下也增加了任务的复杂性,学习准确动态模型的抽样效率也提高了。然而,许多复杂任务也显示出动态的广度,即,行动对系统动态只有局部影响。在本文件中,我们利用这种属性,在单一任务设置中,从因果变异的角度来看待单一任务,引入一种新型的州抽象学,称为\ textit{ 模型变异}。与以前的国家抽象学形式不同,模型变异状态的抽象利用使因果关系超过国家变量。这样,许多复杂的任务也显示对不可见国家的构成性概括性概括性,而非因素形式的状态抽象则无法对系统动态产生局部影响。我们证明,在模型变异性状态的抽象学中可以学习最佳政策,并显示在一个简单到的域内改进的通用化。我们提出了一个实用的方法,来大致学习复杂域的模型变异性代表,并通过显示在标准可能性上改进的模型性工作上的表现来影响国家变异性变异性变量。 最终显示我们公司内部的连续性业绩。