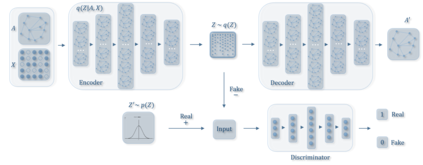
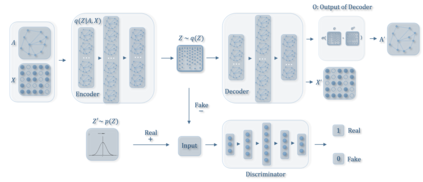
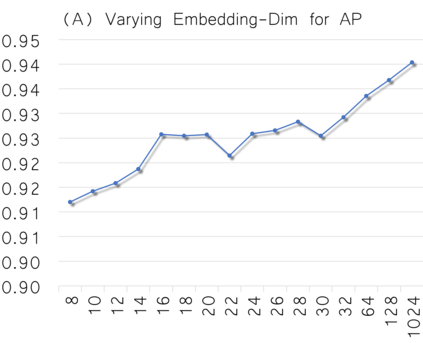
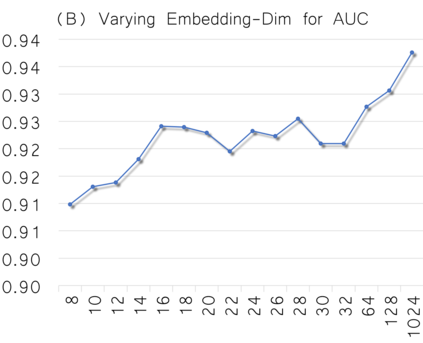
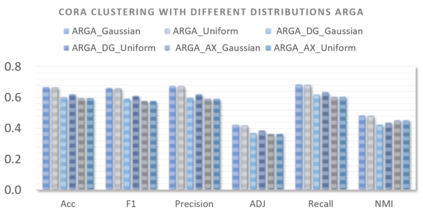
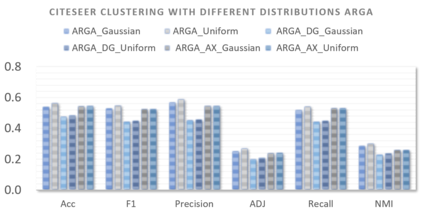
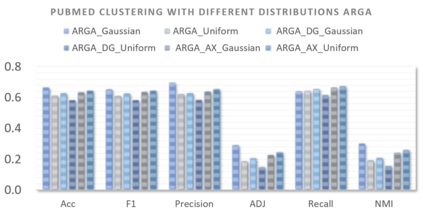
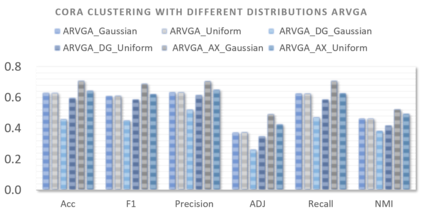
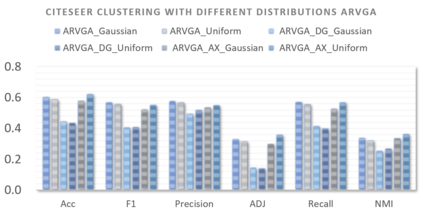
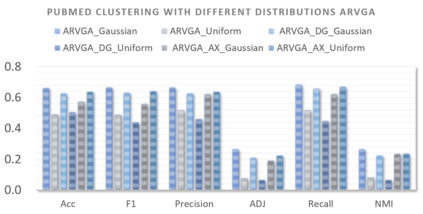
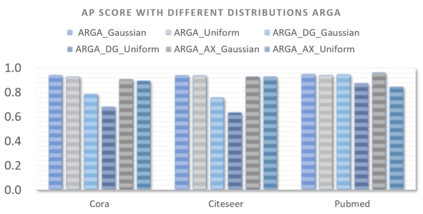
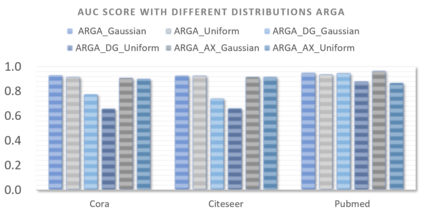
Graph embedding aims to transfer a graph into vectors to facilitate subsequent graph analytics tasks like link prediction and graph clustering. Most approaches on graph embedding focus on preserving the graph structure or minimizing the reconstruction errors for graph data. They have mostly overlooked the embedding distribution of the latent codes, which unfortunately may lead to inferior representation in many cases. In this paper, we present a novel adversarially regularized framework for graph embedding. By employing the graph convolutional network as an encoder, our framework embeds the topological information and node content into a vector representation, from which a graph decoder is further built to reconstruct the input graph. The adversarial training principle is applied to enforce our latent codes to match a prior Gaussian or Uniform distribution. Based on this framework, we derive two variants of adversarial models, the adversarially regularized graph autoencoder (ARGA) and its variational version, adversarially regularized variational graph autoencoder (ARVGA), to learn the graph embedding effectively. We also exploit other potential variations of ARGA and ARVGA to get a deeper understanding on our designs. Experimental results compared among twelve algorithms for link prediction and twenty algorithms for graph clustering validate our solutions.
翻译:嵌入的图形旨在将一个图形转换成矢量,以便利随后的图形分析任务,如链接预测和图形群集。图形嵌入的大多数方法侧重于保存图形结构或尽量减少图形数据重建错误。它们大多忽视潜伏代码的嵌入分布,这在很多情况下可能导致代表比例低。在本文件中,我们提出了一个新的对抗性固定化图形嵌入框架。通过将图形共变网络用作编码器,我们的框架将表层信息和节点内容嵌入矢量代表器,从中进一步构建一个图形解码器以重建输入图。对抗性培训原则用于执行我们的潜在代码,以匹配先前的Gaussian或统一分布。基于这个框架,我们得出了两种对抗性典型的变式,即对抗性正规化图形自动编码(ARGA)及其变式版本,即对抗性正规化变异图形自动编码(ARVGA),以便有效地学习图表嵌入。我们还利用了ARGA和ARVGA的其他潜在变异,以使我们的模型能够更深入地了解我们的12项矩阵模型。