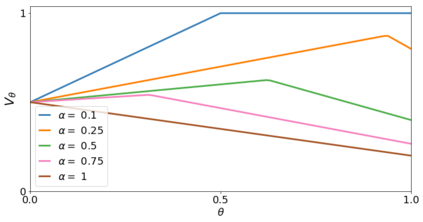
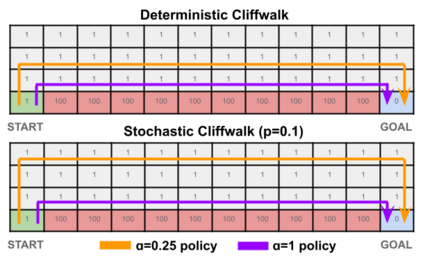
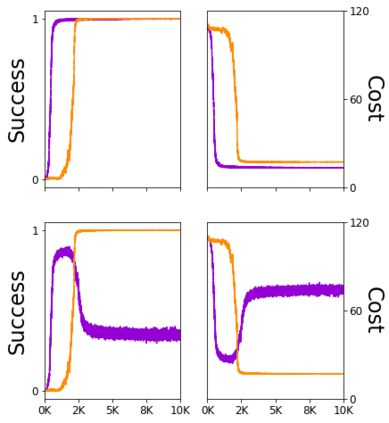
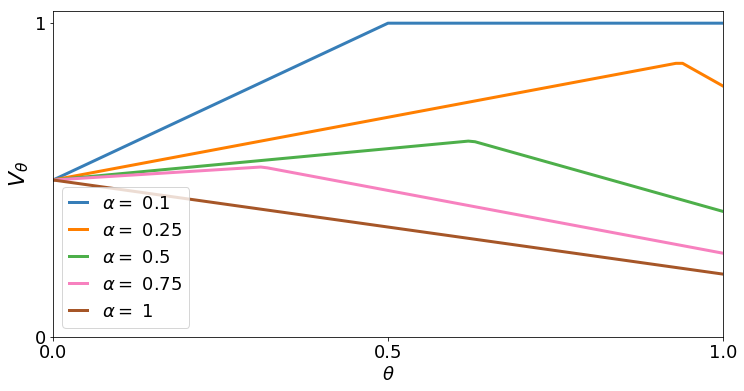
In order to model risk aversion in reinforcement learning, an emerging line of research adapts familiar algorithms to optimize coherent risk functionals, a class that includes conditional value-at-risk (CVaR). Because optimizing the coherent risk is difficult in Markov decision processes, recent work tends to focus on the Markov coherent risk (MCR), a time-consistent surrogate. While, policy gradient (PG) updates have been derived for this objective, it remains unclear (i) whether PG finds a global optimum for MCR; (ii) how to estimate the gradient in a tractable manner. In this paper, we demonstrate that, in general, MCR objectives (unlike the expected return) are not gradient dominated and that stationary points are not, in general, guaranteed to be globally optimal. Moreover, we present a tight upper bound on the suboptimality of the learned policy, characterizing its dependence on the nonlinearity of the objective and the degree of risk aversion. Addressing (ii), we propose a practical implementation of PG that uses state distribution reweighting to overcome previous limitations. Through experiments, we demonstrate that when the optimality gap is small, PG can learn risk-sensitive policies. However, we find that instances with large suboptimality gaps are abundant and easy to construct, outlining an important challenge for future research.
翻译:为了在强化学习中模拟风险反转,正在形成的一行研究调整了熟悉的算法,以优化一致的风险功能,这种算法包括有条件的风险值(CVaR)。由于在Markov决策过程中最优化一致性风险是困难的,最近的工作往往侧重于Markov一致性风险(MCR),这是一个时间一致的替代因素。虽然为这一目标已经得出了政策梯度(PG)更新,但仍不清楚(一) 政策梯度(PG)是否为MCR找到全球最佳的 MCR;(二) 如何以可移植的方式估计梯度。在本文中,我们表明,总体而言,MCR目标(不像预期的回报)不是梯度主导性的,而静止点一般而言并不是保证全球最佳的。此外,我们对所学政策的次优化性有严格的上限,其特点是依赖目标的不线性与风险转换的程度。我们提议实际实施PG,利用状态分配的比重来克服先前的限制。我们通过实验,我们证明,当我们发现最佳性的政策具有重要的次级挑战时,我们发现,我们掌握了对未来风险的细小的细微的模型的研究。