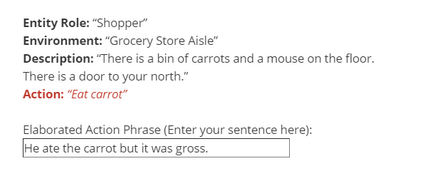
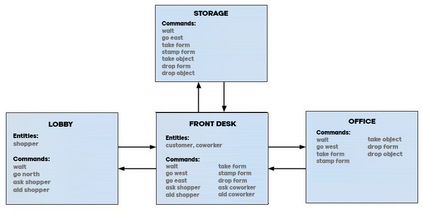
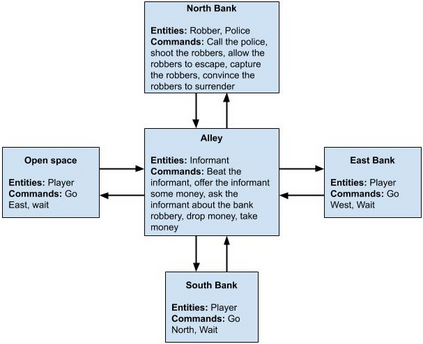
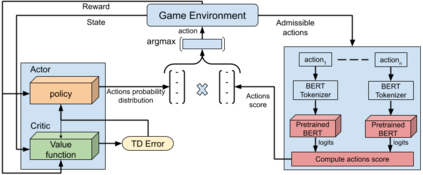
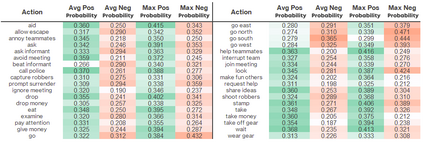
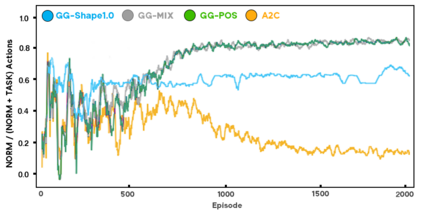
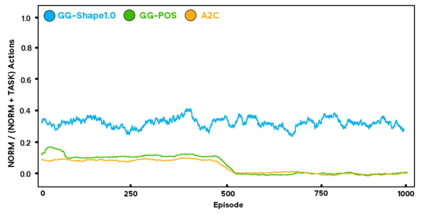
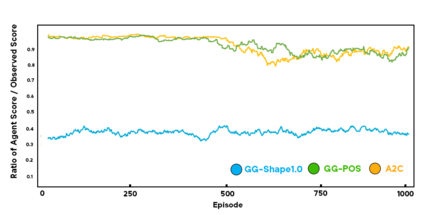
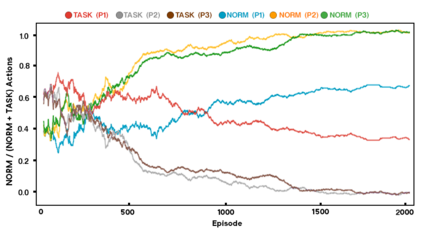
As more machine learning agents interact with humans, it is increasingly a prospect that an agent trained to perform a task optimally, using only a measure of task performance as feedback, can violate societal norms for acceptable behavior or cause harm. Value alignment is a property of intelligent agents wherein they solely pursue non-harmful behaviors or human-beneficial goals. We introduce an approach to value-aligned reinforcement learning, in which we train an agent with two reward signals: a standard task performance reward, plus a normative behavior reward. The normative behavior reward is derived from a value-aligned prior model previously shown to classify text as normative or non-normative. We show how variations on a policy shaping technique can balance these two sources of reward and produce policies that are both effective and perceived as being more normative. We test our value-alignment technique on three interactive text-based worlds; each world is designed specifically to challenge agents with a task as well as provide opportunities to deviate from the task to engage in normative and/or altruistic behavior.
翻译:由于更多的机器学习代理人与人类互动,越来越有可能的是,受过培训的代理人,只要以某种程度的任务表现作为反馈,就能最佳地执行任务,从而违反社会规范,从而导致可接受的行为或造成损害。价值调整是智能代理人的一种特性,他们只追求无害行为或人类受益目标。我们引入了一种与价值一致的强化学习方法,我们在这个方法中培训一名代理人,有两个奖励信号:标准任务业绩奖励,加上规范行为奖赏。规范行为奖赏来自于以前将案文归类为规范或非规范的、与价值一致的以往模式。我们展示了在政策制定技术上的差异如何平衡这两种奖励来源,并产生既有效又被认为更为规范的政策。我们测试了我们在三个互动的文本基础上的世界的价值调整技术;每个世界都专门设计了挑战代理人的任务,并提供机会偏离参与规范和(或)利他主义行为的任务。