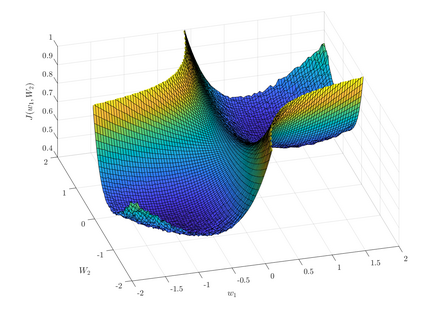
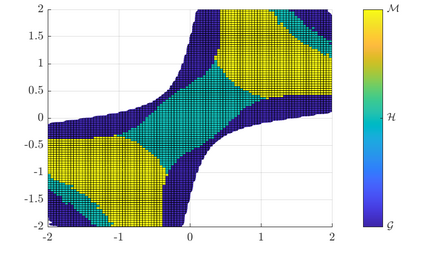
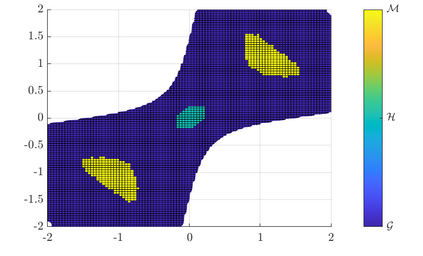
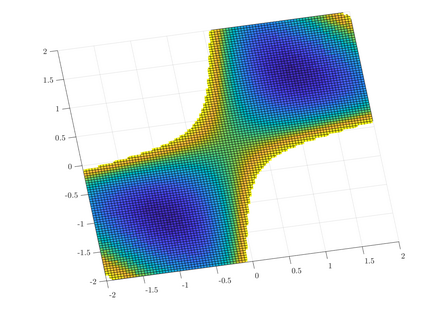
Rapid advances in data collection and processing capabilities have allowed for the use of increasingly complex models that give rise to nonconvex optimization problems. These formulations, however, can be arbitrarily difficult to solve in general, in the sense that even simply verifying that a given point is a local minimum can be NP-hard [1]. Still, some relatively simple algorithms have been shown to lead to surprisingly good empirical results in many contexts of interest. Perhaps the most prominent example is the success of the backpropagation algorithm for training neural networks. Several recent works have pursued rigorous analytical justification for this phenomenon by studying the structure of the nonconvex optimization problems and establishing that simple algorithms, such as gradient descent and its variations, perform well in converging towards local minima and avoiding saddle-points. A key insight in these analyses is that gradient perturbations play a critical role in allowing local descent algorithms to efficiently distinguish desirable from undesirable stationary points and escape from the latter. In this article, we cover recent results on second-order guarantees for stochastic first-order optimization algorithms in centralized, federated, and decentralized architectures.
翻译:数据收集和处理能力方面的快速进步使得能够使用日益复杂的模型,从而产生非凝固优化问题,但这些配方一般可能难以任意解决,因为即使简单地核实某一点是当地最低点,也可以是NP-hard[1]。不过,一些相对简单的算法已经证明在许多感兴趣的环境中可以带来令人惊讶的良好经验结果。也许最突出的例子是培训神经网络的反向调整算法的成功。最近的一些工程通过研究非凝固优化问题的结构,确定简单的算法,例如梯度下降及其变异,在与当地微型相融合和避免马鞍点方面表现良好,为这一现象寻求严格的分析理由。这些分析的一个重要见解是,梯度扰动对于允许当地血统算法有效地区分可取的固定点和脱离后者起着关键作用。在本篇文章中,我们介绍了关于集中、节制和分散结构中第二阶次的一级优化算法的最新结果。