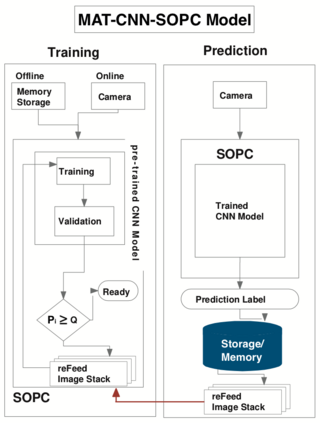
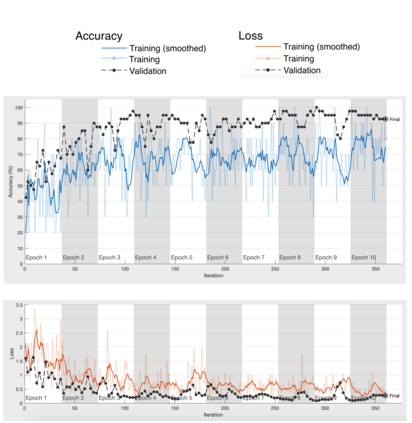
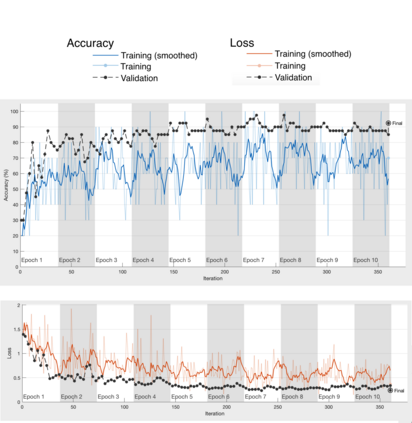
Intelligent Transportation Systems (ITS) have become an important pillar in modern "smart city" framework which demands intelligent involvement of machines. Traffic load recognition can be categorized as an important and challenging issue for such systems. Recently, Convolutional Neural Network (CNN) models have drawn considerable amount of interest in many areas such as weather classification, human rights violation detection through images, due to its accurate prediction capabilities. This work tackles real-life traffic load recognition problem on System-On-a-Programmable-Chip (SOPC) platform and coin it as MAT-CNN- SOPC, which uses an intelligent re-training mechanism of the CNN with known environments. The proposed methodology is capable of enhancing the efficacy of the approach by 2.44x in comparison to the state-of-art and proven through experimental analysis. We have also introduced a mathematical equation, which is capable of quantifying the suitability of using different CNN models over the other for a particular application based implementation.
翻译:智能交通系统(ITS)已成为现代“智能城市”框架的重要支柱,要求机器的智能参与。交通负荷识别可被归类为这类系统的一个重要和具有挑战性的问题。最近,革命神经网络模型因其准确的预测能力,在许多领域吸引了相当大的兴趣,如天气分类、通过图像探测侵犯人权情况等。这项工作解决了在系统在线方案芯片(SOPC)平台上的真实生活交通负荷识别问题,并把它作为MAT-CNN-SOPC,它使用CNN有已知环境的智能再培训机制。拟议的方法能够提高2.44x的方法在最新技术方面的效率,并通过实验分析加以验证。我们还引入了数学等式,它能够量化使用不同的CNN模型对另一个应用实施特定应用的适宜性。