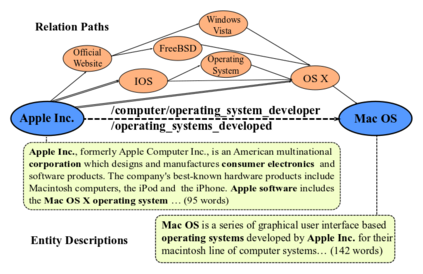
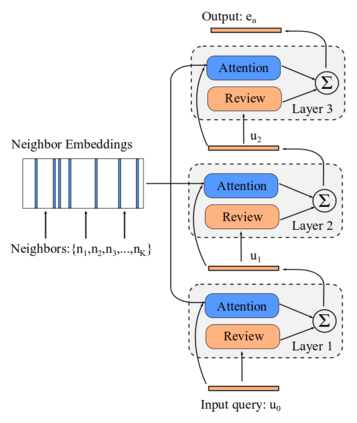
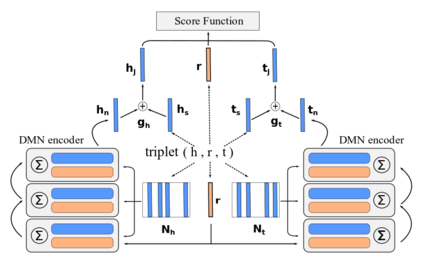
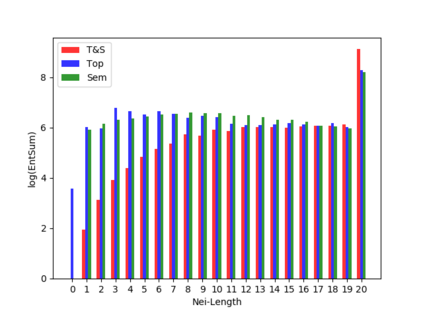
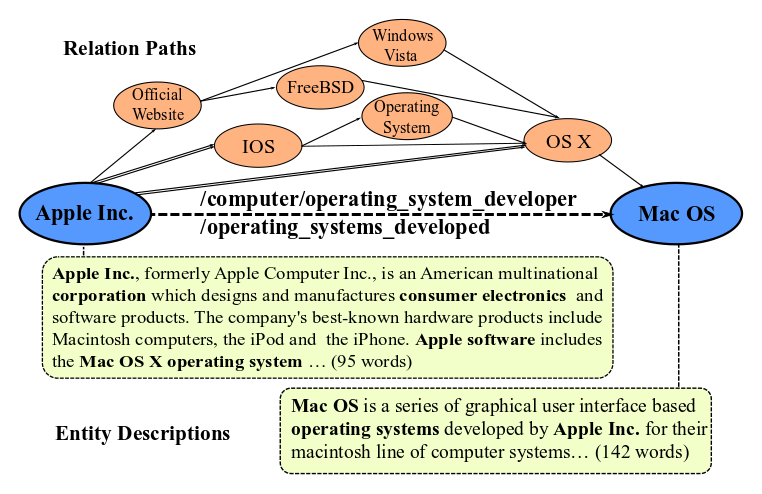
Knowledge Graph Embedding (KGE) aims to represent entities and relations of knowledge graph in a low-dimensional continuous vector space. Recent works focus on incorporating structural knowledge with additional information, such as entity descriptions, relation paths and so on. However, common used additional information usually contains plenty of noise, which makes it hard to learn valuable representation. In this paper, we propose a new kind of additional information, called entity neighbors, which contain both semantic and topological features about given entity. We then develop a deep memory network model to encode information from neighbors. Employing a gating mechanism, representations of structure and neighbors are integrated into a joint representation. The experimental results show that our model outperforms existing KGE methods utilizing entity descriptions and achieves state-of-the-art metrics on 4 datasets.
翻译:知识嵌入图(KGE)旨在代表一个低维持续矢量空间中的实体和知识图关系。最近的工作重点是将结构知识与更多信息相结合,如实体描述、关系路径等。然而,常用的额外信息通常含有大量噪音,因此难以获得有价值的表述。在本文中,我们提议了一种新型的额外信息,称为实体邻居,其中含有特定实体的语义和地形特征。然后,我们开发了一个深厚的记忆网络模型,以编码来自邻居的信息。使用一种定位机制、结构和邻居的表示方式被整合到一个联合代表中。实验结果显示,我们的模型利用实体描述和在4个数据集上实现最新指标,优于现有的KGE方法。